Canal
Canal概述
官方文档: 传送门
Canal的起源
阿里巴巴 B2B 公司, 因为业务的特性, 卖家主要集中在国内, 买家主要集中在国外, 所以衍生出了同步杭州和美国异地机房的需求, 从2010年开始, 阿里系公司开始逐步的尝试基于数据库的日志解析, 获取增量变更进行同步, 由此衍生出了增量 订阅&消费 的业务.
Canal 是用 Java 开发的基于数据库增量日志解析, 提供增量数据 订阅&消费 的中间件. 目前, Canal 主要支持了 MySQL 的 Binlog 解析, 解析完成后才利用 Canal Client 来处理获得的相关数据. (数据库同步需要阿里的 Otter 中间件, 基于 Canal ).
MySQL的Binlog
什么是Binlog
MySQL 的二进制日志可以说是 MySQL 最重要的日志了, 它记录了所有的 DDL 和 DML (除了数据查询语句) 语句, 以事件行驶记录, 还包括语句所执行的消耗的时间.
Binlog是事务安全性的.
一般来说, SQL语言分为三类:
DML(Data Manipulation Language): 数据操纵语言, 最常用的增删改查就是这类, 操作对象是数据表中的记录DDL(Data Definition Language): 数据定义语言, 例如建库、建表等DCL(Data Control Language): 数据控制语言, 如 Grant、Rollback 等, 常见于数据库安全管理
Binlog两个最重要的使用场景:
- MySQL Replication 在 Master 端开启 Binlog, Master 把它的 Binlog 传递给 Slaves 来达到 Master-Slave 数据一致的目的
- 数据恢复, 通过使用 MySQL Binlog 工具来使恢复数据
Binlog分类
MySQL Binlog 的格式有三种, 分别是 STATEMENT,MIXED,ROW . 在配置文件中可以选配: binlog_format=statement|mixed|row
statement: 语句级, binlog 会记录每次执行写操作的语句. 相对row模式节省空间, 但是可能产生不一致性. 🌰:update table set create_date=now(), 如果用这种模式进行恢复, 由于执行时间的不同产生的数据就可能不同.- 优势: 节省空间
- 劣势: 可能造成数据不一致
row: 行级, binlog 会记录每次操作后每行记录的变化.- 优势: 保持数据的绝对一致性
- 劣势: 占用空间大
mixed: statement的升级版, 一定程度上解决了因为一些情况而造成的 statement模式 不一致的问题. mixed默认还是statement, 在某些情况下(🌰): 当函数中包含UUID()时; 包含AUTO_INCREMENT字段的表被更新等. 这些情况下会按照row的方式处理.- 优势: 节省空间, 同事兼顾了一定的一致性
- 劣势: 还有一些极个别情况依旧会造成不一致, 另外 statement 和 mixed 对于需要对 binlog 的监控情况都不方便
综上, Canl想做监控分析, 选择 row 格式比较合适
Canal的工作原理
MySQL主从复制过程
- Master 主库将改变记录, 写到 binlog 中;
- Slave 从库向 MySQL Slave 发送 dump 协议, 将 Master 主库的 binlog events 拷贝到它的中继日志(relay log);
- Slave 从库读取并重做中继日志中的事件, 将改变的数据同步到自己的数据库.
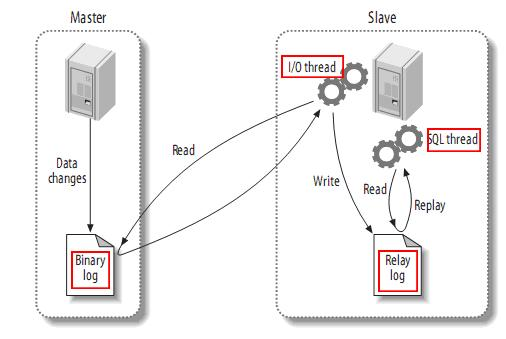
Canal的工作原理
理解了上面的过程, Canal的原理就很简单, 就是把自己伪装成Slave, 假装从 Master 复制数据
MySQL的准备
MySQL的安装这里就不说了, 网上有很多.
-
首先, 建数据库:
canal_test -
然后建表:
1 2 3 4 5create table user_info { `id` int, `name` varchar(255), `gender` varchar(255) } -
修改配置文件开启binlog
1 2 3 4 5 6 7 8 9[root@hadoop102 ~]# vi /etc/my.cnf # 打开binlog log-bin=mysql-bin # 选择ROW模式 binlog-format=row # 配置MYSQL replaction需要定义, 不要和canal的slaveId重复 server_id=1 binlog-do-db=canal_testbinlog-do-db根据实际情况配置, 如果不配置, 则表示所有数据库均开启 binlog. -
重启 MySQL
1sudo systemctl restart mysqld
Canal的下载和安装
下载
下载地址: https://github.com/alibaba/canal/releases
-
下载对应版本:
canal.deployer-xxx.tar.gz -
解压到对应位置
修改 canal.properties
|
|
这个文件是 canal 的基本通用配置, canal端口号默认是11111.
多实例配置: 一个 canal 服务中可以有多个instance, conf/ 下每一个 example 即是一个实例, 每个实例下面都有独立的配置文件. 需修改canal.destinations=实例1,实例2,实例3
修改 instance.properties
|
|
|
|
实时监控测试
TCP模式测试
-
创建一个 maven 项目, 在
pom.xml中配置:1 2 3 4 5<dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.client</artifactId> <version>1.1.2</version> </dependency> -
创建类:
CanalClient1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83package org.mustard.app; import com.alibaba.fastjson.JSONObject; import com.alibaba.otter.canal.client.CanalConnector; import com.alibaba.otter.canal.client.CanalConnectors; import com.alibaba.otter.canal.protocol.CanalEntry; import com.alibaba.otter.canal.protocol.Message; import com.google.protobuf.ByteString; import com.google.protobuf.InvalidProtocolBufferException; import java.net.InetSocketAddress; import java.util.List; public class CanalClient { public static void main(String[] args) throws InvalidProtocolBufferException { // 获取连接对象 CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("hadoop102", 11111), "example", "", ""); // 获取连接 canalConnector.connect(); // 指定要监控的数据库 canalConnector.subscribe("canal.*"); long idx = 0; while (true) { // 获取message Message msg = canalConnector.get(100); List<CanalEntry.Entry> entries = msg.getEntries(); if (entries.size() <= 0) { System.out.println((++idx) + ". 没有数据, 等一会儿"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } else { for (CanalEntry.Entry entry : entries) { // 获取表名 String tableName = entry.getHeader().getTableName(); // Entry类型 CanalEntry.EntryType entryType = entry.getEntryType(); if (CanalEntry.EntryType.ROWDATA.equals(entryType)) { // 序列化数据 ByteString storeValue = entry.getStoreValue(); // 反序列化 CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue); // 获取事件类型 CanalEntry.EventType eventType = rowChange.getEventType(); // 获取具体数据 List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList(); // 遍历打印 for (CanalEntry.RowData rowData : rowDatasList) { List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList(); JSONObject beforeData = new JSONObject(); for (CanalEntry.Column column : beforeColumnsList) { beforeData.put(column.getName(), column.getValue()); } List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList(); JSONObject afterData = new JSONObject(); for (CanalEntry.Column column : afterColumnsList) { afterData.put(column.getName(), column.getValue()); } System.out.println("TableName: " + tableName + ", EventType: " + eventType + ", Before: " + beforeData + ", After: " + afterData); } } } } } } }
Kafka模式测试
-
修改 canal.properties 中 canal 的输出 model
1 2 3 4 5 6 7 8 9 10 11 12######### common argument ############# canal.id = 1 canal.ip = canal.port = 11111 canal.metrics.pull.port = 11112 canal.zkServers = # flush data to zk canal.zookeeper.flush.period = 1000 canal.withoutNetty = false # tcp, kafka, RocketMQ canal.serverMode = kafka # flush meta cursor/parse position to file -
修改 kafka 集群的地址
1 2######### Kafka ############# kafka.bootstrap.servers = hadoop102:9092 -
修改 instance.properties 输出到 Kafka 的主题以及分区数
1 2# mq config canal.mq.topic=canal_test默认还是输出到指定 Kafka 主题的一个分区, 因为多个分区并行可能会打乱 binlog 的顺序, 如果要提高并行度, 首先设置 kafka 的分区数 > 1, 然后设置
canal.mq.partitionHash属性. -
启动 canal
1$ ./bin/startup.sh -
然后测试:
1 2 3[root@hadoop102 kafka_2.12-2.8.1]# ./bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic canal_test {"data":[{"id":"5","name":"aria","gender":"female"}],"database":"canal_test","es":1658589672000,"id":2,"isDdl":false,"mysqlType":{"id":"int(11)","name":"varchar(255)","gender":"varchar(255)"},"old":null,"pkNames":null,"sql":"","sqlType":{"id":4,"name":12,"gender":12},"table":"user_info","ts":1658589672852,"type":"DELETE"} {"data":[{"id":"5","name":"aria","gender":"female"}],"database":"canal_test","es":1658589697000,"id":3,"isDdl":false,"mysqlType":{"id":"int(11)","name":"varchar(255)","gender":"varchar(255)"},"old":null,"pkNames":null,"sql":"","sqlType":{"id":4,"name":12,"gender":12},"table":"user_info","ts":1658589697570,"type":"INSERT"}