常用数据库选型
Common Database Selection
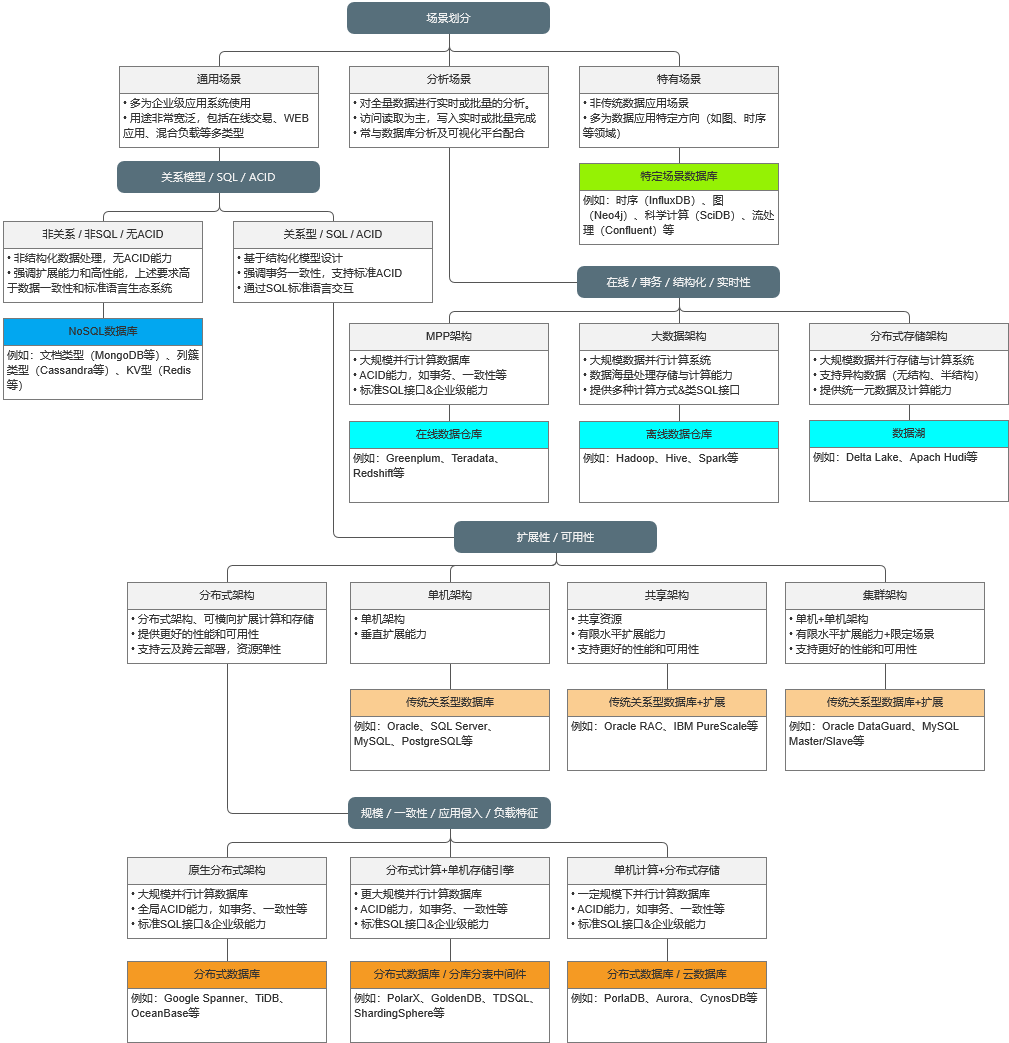
现在数据库的选型有很多, 想总结一下常用数据库的选型依据.
影响数据库的因素
- 数据量: 是否海量数据, 一般考虑的是单表数据量
- 数据结构: 结构化还是非结构化 (每条记录的结构是一样的还是不一样)
- 是否宽表: 一条记录是 10 个字段还是成百上千个字段
- 数据属性: 是基本数据 (用户信息等)、业务数据 (用户行为等)、辅助数据 (日志等)、缓存数据
- 是否要求事务性: 一个事物由多个操作组成, 必须全部成功或全部回滚
- 实时性: 从读写两个方面来看, 是需要读实时性还是写实时性
- 查询量: 比如有的业务要求查询大量记录的少数列, 有的要求查询少数记录的所有列
- 排序
- 可靠性要求: 对数据丢失的容忍度
- 一致性要求: 是否要求读到的一定是最新写入的数据
- 对 CRUD 的要求: 有的业务要能快速的对单条数据做 CRUD (用户信息), 有的要求批量导入, 有的不需要修改删除单条记录 (日志、用户行为), 有的要求检索少量数据 (日志), 有的要求快速读取大量数据 (展示报表), 有的要求大量读取并计算数据 (分析用户行为)
- 是否支持多表操作
常见分类
| 数据库类型 | 常见数据库 |
|---|---|
| 关系型 (Sql) | MySQL, Oracle, PostgreSQL, DB2, SQLServer, etc. |
| 非关系型 (NoSql) | Hbase, Redis, MongoDB, etc. |
| 行式存储 | MySQL, Oracle, DB2, SQLServer, etc. |
| 列式存储 | Hbase, ClickHouse, etc. |
| 分布式存储 | Cassandra, Hbase, MongoDB, etc. |
| 键值存储 | Memcached, Redis, etc. |
| 图形存储 | Neo4J, TigerGraph, etc. |
| 文档存储 | MongoDB, CouchDB, etc. |
关系型数据库
MySQL
-
优点:
- 开源和免费: MySQL 是开源软件, 可以免费使用, 这使得它对于许多组织和项目来说成本效益很高
- 跨平台支持: 可运行在多种操作系统上, 包括 Linux, Windows, macOS 等.
- 社区支持: 拥有庞大的开源社区, 也就意味着可以找到大量的文档, 教程和支持资源
- 高性能: 针对读操作和写操作都具有良好的性能. 支持多种存储引擎, 比如 InnoDB, myISAM 等.
- 可扩展性: 支持主从复制, 分区表等特性, 可以用于构建高可用性和可扩展的数据库架构.
- 事务支持: 支持 ACID (原子性, 一致性, 隔离性和持久性) 属性, , 使其适用于需要强一致性的应用程序.
- 丰富的功能集: 提供了许多功能, 包括存储过程、触发器、视图、外键等, 以支持复杂的数据库应用程序.
- 安全性: 提供了强大的安全功能, 包括访问控制、SSL支持、数据加密等, 可以帮助保护数据库的安全性.
-
缺点:
-
性能随负载增加而下降: 尽管 MySQL 在一般情况下表现良好, 但在极高负载下性能可能下降, 特别是对于写密集型工作负载.
-
存储引擎限制: 不同的存储引擎具有不同的特性和限制, 选择合适的存储引擎可能会有一些挑战.
-
复杂的配置: MySQL的复杂性可能会导致配置和调整变得困难, 尤其是对于新手来说.
-
有限的分布式支持: MySQL在本地和单一数据中心环境中表现良好, 但在大规模分布式环境中的支持相对有限.
-
**不支持JSON类型 (取决于版本) **: 在早期的 MySQL 版本中, 对 JSON 数据的支持有限, 但在后续版本中进行了改进.
MySQL v5.7 之后支持
JSON数据类型; v8.0 之后提供处理 JOSN 数据的内置函数, 包括JSON_EXTRACT,JSON_SET,JSON_INSERT,JSON_REMOVE等, 并且提供了在 JSON 列上加索引.1 2 3 4 5 6 7 8 9 10CREATE TABLE my_table ( id INT AUTO_INCREMENT PRIMARY KEY, data JSON ); -- 插入JSON数据 INSERT INTO my_table (data) VALUES ('{"name": "John", "age": 30, "city": "New York"}'); -- 查询JSON数据 SELECT data->>'$.name' AS name, data->>'$.age' AS age FROM my_table;
-
MariaDB
说到 MySQL 之后就一定要提一下 MariaDB, 因为 MariaDB 最初是 MySQL 的一个分支, 所以它们的相似性非常大.
-
相似性
-
语法和查询: MariaDB 和 MySQL 共享几乎相同的 SQL 语法和查询语言. 大多数标准SQL查询可以在两者之间无需修改地运行.
-
数据兼容性: 由于 MariaDB 的起源是 MySQL, 因此它们之间的数据兼容性很高. 大多数 MySQL 数据库可以轻松迁移到 MariaDB 而无需进行大规模修改.
-
存储引擎: MariaDB 和 MySQL 支持相同的存储引擎, 如InnoDB、MyISAM等, 这意味着可以在两者之间轻松切换存储引擎.
-
开源性: MariaDB 和 MySQL都是开源的, 可以免费使用, 并且有一个活跃的开发社区支持它们.
-
-
区别
-
开发和维护: MariaDB 的开发是由一个独立的开发团队进行的, 而 MySQL 最初由 MySQL AB 公司维护, 后来被 Sun Microsystems 收购, 然后又被 Oracle Corporation 收购. 这些公司的所有权变更引发了一些担忧, 因此 MariaDB 作为 MySQL 的一个分支在继续开发, 以确保开源性和社区驱动的发展.
-
性能和优化: MariaDB 在某些情况下可能会具有更好的性能和优化特性. 它引入了一些性能改进和新的存储引擎, 例如 Aria 和 TokuDB, 以提供更高的性能和扩展性.
-
功能扩展: MariaDB 在某些方面引入了新的功能, 例如动态列、JSON支持等. 此外, MariaDB 还包括一些 MySQL 未来版本的功能, 如窗口函数, 但可能会在 MariaDB 中更早地得到支持.
-
默认存储引擎: MariaDB 默认的存储引擎是 Aria, 而 MySQL 默认的存储引擎是 InnoDB. 这是一个细微的差异, 但可能需要注意.
-
安全性功能: MariaDB 引入了一些安全性增强功能, 如外部认证插件、密码策略等.
-
Oracle
-
优点:
- 稳定性和可靠性: 以其卓越的稳定性和可靠性而闻名, 适用于高度关键性的应用程序和大型企业环境. 它具有出色的数据完整性和事务处理能力.
- 安全性: 提供了强大的安全功能, 包括高级的权限控制、身份验证、加密和审计功能, 可保护敏感数据不受未经授权的访问.
- 性能优化: 提供了丰富的性能调整工具和功能, 如查询优化器、索引、分区表、缓存和存储过程, 以帮助优化数据库性能.
- 扩展性: 支持高度可扩展的架构, 可应对大规模数据需求, 包括数据分片、集群和分布式数据库.
- 多平台支持: 支持多个操作系统, 包括各种 UNIX 变体、Linux 和 Windows, 因此可以在不同的硬件和软件环境中运行.
- 备份和恢复: 提供了强大的备份和恢复功能, 包括点播备份、增量备份和恢复到特定时间点等选项, 以确保数据的可靠性和可恢复性.
- 企业支持: 提供了广泛的企业级支持和培训资源, 以帮助客户有效地管理和维护其数据库系统.
-
缺点:
- 高成本: 数据库和相关的支持和许可费用通常很高, 这使得它在小型和中小型企业中不太适用.
- 复杂性: 数据库的配置和管理通常比较复杂, 需要专业知识. 这可能对初学者和小型团队构成挑战.
- 资源消耗: 需要大量的计算和内存资源, 因此在资源有限的环境中可能表现不佳.
- 许可限制: 数据库的许可政策比较严格, 需要严格遵守许可条款, 否则可能会导致法律问题.
PostgreSQL
- 优点:
- 开源: 开源软件, 可以免费使用、修改和分发. 这降低了使用和部署的成本, 并且使其对开发人员和组织来说更加可行.
- 高级功能: 提供了丰富的高级功能, 包括复杂的数据类型 (如数组、JSON、几何类型) 、全文搜索、地理信息系统 (GIS) 支持、窗口函数、通用表达式 (CTE) 等等.
- 可扩展性: 具有出色的可扩展性, 支持分布式计算、复制、分区表等功能, 使其适用于大规模和高并发的应用程序.
- 标准兼容性: 严格遵循SQL标准, 同时还支持许多其他数据库系统的扩展SQL语法, 使迁移和集成变得更容易.
- 扩展性和自定义性: 支持用户自定义的函数、操作符和聚合函数, 允许开发人员根据特定需求扩展数据库功能.
- 社区支持: 拥有庞大的全球社区, 提供了丰富的文档、在线资源和第三方插件, 以帮助用户解决问题和扩展功能.
- 安全性: 提供了强大的安全功能, 包括SSL支持、数据加密、身份验证和访问控制, 以保护敏感数据.
- 并发控制: 使用多版本并发控制 (MVCC) 来管理事务, 允许多个事务同时进行, 不会相互干扰, 提高了并发性能.
- 缺点:
- 性能: 虽然性能很好, 但在某些情况下, 特别是与一些商业数据库相比, 可能会稍逊一筹. 性能问题通常可以通过合理的配置和索引来优化.
- 学习曲线: 对于初学者来说, 可能有一定的学习曲线, 特别是对于那些没有经验的用户. 但一旦熟悉了它, 就会发现它非常强大.
- 工具生态系统: 尽管有很多支持工具和扩展, 但与一些其他数据库 (如MySQL和Oracle) 相比, 其生态系统可能相对较小.
- 管理复杂性: 管理数据库可能需要更多的手动操作和配置, 特别是在大规模和复杂的环境中.
SQL Server
- 优点:
- 易用性: 在用户友好性方面表现出色, 具有直观的图形用户界面 (SQL Server Management Studio) 和易于使用的工具. 这使得它成为初学者和有经验的数据库管理员的首选.
- 集成性: 与其他Microsoft产品 (如Windows Server、Active Directory、Azure云服务等) 紧密集成, 这使得它在Microsoft生态系统中的部署和管理更加方便.
- 强大的商业支持: 提供了广泛的商业支持和培训资源, 包括定期的安全更新、维护计划和专业的技术支持.
- 安全性: 提供了强大的安全功能, 包括访问控制、数据加密、审计和身份验证, 以确保数据的安全性.
- 高可用性: 支持高可用性功能, 如故障转移集群、数据库镜像、Always On可用性组等, 以确保数据的可用性和冗余.
- 性能优化: 提供了性能优化工具和功能, 如查询优化器、索引、缓存和执行计划分析工具, 有助于提高查询性能.
- 分析服务: 包括分析服务, 支持数据仓库和数据分析, 包括OLAP (联机分析处理) 和数据挖掘.
- 跨平台支持: 最新版本提供了跨平台支持, 可以在Linux操作系统上运行, 扩展了其部署选项.
- 缺点:
- 成本: 商业数据库系统, 需要购买许可证. 其成本相对较高, 特别是对于小型和中小型企业.
- 资源消耗: 通常需要大量计算和内存资源, 因此在资源有限的环境中可能表现不佳.
- 可移植性: 与Microsoft产品集成紧密, 这可能导致在其他平台上的移植和集成方面的挑战.
- 学习曲线: 对于初学者来说, 可能具有一定的学习曲线, 特别是对于那些不熟悉Microsoft技术的人.
- 限制: 不同版本有不同的功能限制, 一些高级功能可能只在较高级别的版本中可用.
DB2
- 优点:
- 可扩展性和性能: Db2具有出色的可扩展性, 适用于处理大规模数据和高并发的应用程序. 它在性能方面表现出色, 支持高效的查询优化和并发控制.
- 多平台支持: Db2可以在多个操作系统上运行, 包括各种UNIX平台、Linux和Windows. 这使得它适用于不同的硬件和操作系统环境.
- 高可用性: Db2提供了高可用性和容错功能, 包括故障转移集群、自动故障检测和恢复. 这有助于确保数据的可用性和冗余.
- 安全性: Db2提供了强大的安全功能, 包括访问控制、数据加密、审计和身份验证, 以保护数据的机密性和完整性.
- 多样性的数据类型: Db2支持多种数据类型, 包括文本、图像、音频和视频等非结构化数据. 这使得它适用于处理各种数据.
- SQL标准兼容性: Db2严格遵循SQL标准, 同时还支持一些扩展SQL语法, 这有助于开发人员轻松迁移和集成应用程序.
- 强大的工具和生态系统: Db2拥有丰富的工具和生态系统, 包括图形用户界面工具、ETL工具、报表工具等, 以及第三方插件和扩展.
- 缺点:
- 成本: Db2是商业数据库系统, 需要购买许可证, 因此成本较高. 这可能对小型和中小型企业的预算造成压力.
- 学习曲线: 对于初学者来说, Db2可能有一定的学习曲线, 特别是对于没有Db2经验的用户. 它可能需要更多的培训和学习时间.
- 复杂性: 在某些情况下, Db2的配置和管理可能比较复杂, 特别是在大规模和高度定制的环境中.
- 限制: 不同版本的Db2具有不同的功能限制, 一些高级功能可能只在较高级别的版本中可用.
总结
| 方面 | MySQL | Oracle | Postgres | SQL Server | DB2 |
|---|---|---|---|---|---|
| 免费版本 | 可自由使用和修改 | 提供 XE 版本, 有限制 | 完全免费 | 提供 XE 版本, 有限制 | 提供 Express-C 版本, 有限制 |
| 商业版本 | 提供高级功能和支持 | 贵 | 无商业版本 | 根据版本和功能收费不同, 贵 | 贵 |
| 场景 | 通常在中小型应用程序和网站的性能表现良好, 具有较低的资源消耗, 适用于中低等负载的应用 | 特别适用于大规模企业级应用. 具有卓越的性能优化工具和功能 | 在大中型应用程序中表现出色. 具有强大的查询优化器和高级功能 | 适用于大中型应用程序. 不同版本有所不同 | 特别适用于大规模企业级应用. 支持复发查询和高并发 |
| 可扩展性 | 可通过复制和分片实现可扩展性, 但在大规模和高并发情况下可能需要更多的调整和优化 | 支持分布式架构和高可用性能配置, 可轻松扩展以满足高负载需求 | 支持分布式计算, 分区表和复制. | 支持复制, Always On 可用性组件等功能 | 支持分布式计算, 分区表和复制. 可轻松扩展以满足高负载需求 |
| 认证和授权 | 提供了用户身份验证和授权功能, 允许管理员定义用户和他们的权限 | 提供了高级的认证和授权机制, 包括强大的角色管理和权限控制 | 提供灵活的用户身份验证和授权功能, 允许自定义角色和权限 | 具有强大的身份验证和授权功能, 包括Windows集成身份验证和角色管理 | 提供灵活的认证和授权功能, 支持LDAP和Kerberos身份验证 |
| 加密 | 数据传输的 SSL/TLS 加密. MySQL Enterprise Edition 提供了数据加密和密钥管理功能 | 数据传输的 SSL/TLS 加密、数据列级加密、透明数据加密 (TDE) 以及加密存储. Oracle Advanced Security选项提供了高级的加密和安全性功能 | 数据传输的 SSL/TLS 加密、数据列级加密、透明数据加密 (TDE) 以及加密存储 | 数据传输的 SSL/TLS 加密、数据列级加密、透明数据加密 (TDE) 以及加密存储 | 数据传输的 SSL/TLS 加密、数据列级加密、透明数据加密 (TDE) 以及加密存储. 支持使用Hardware Security Modules (HSMs) 来管理加密密钥 |
| 审计 | MySQL Enterprise Edition提供了审计和监控数据库操作的功能 | 提供了审计和监控数据库操作的功能 | 可以配置审计功能, 但通常需要第三方插件 | 提供了审计和监控数据库操作的功能 | 提供了审计和监控数据库操作的功能 |
| 访问控制 | 支持IP地址白名单和黑名单 | 支持高级的访问控制功能, 如虚拟专用数据库 (VPD) | 支持IP地址白名单和黑名单, 支持行级安全性策略 | 复杂的访问控制机制和IP过滤 | 细粒度的访问控制, 允许管理员定义访问策略 |
| 学习成本 | 较低, 有广泛的文档和社区支持 | 较高, 培训和学习资料可能需要更高的投资 | 中等, 有丰富的文档和社区支持 | 因版本而已 | 较高, 培训和学习资料可能需要更高的投资 |
非关系行数据库
因为 NoSQL 数据库会根据使用场景不用不同而具有完全不同的类型, 所以会根据存储数据类型来进行对比.
文档数据库
MongoDB
-
优点:
-
灵活的模式设计:采用文档存储格式, 每个文档可以有不同的字段和结构. 这种灵活性使其非常适合存储半结构化或不规则数据.
-
横向可扩展性:支持分布式架构, 可以通过添加更多的节点来实现水平扩展, 以处理大量数据和高并发请求.
-
快速的读写操作:在某些情况下能够提供高性能的读写操作, 特别是对于一些简单的查询. 它可以通过适当的索引来提高查询性能.
-
丰富的查询功能:支持复杂的查询, 包括范围查询、全文搜索、地理空间查询等.
-
内置的复制和容错性:支持数据复制和容错, 通过复制集和分片来确保数据的可用性和冗余备份.
-
社区和生态系统:拥有庞大的社区和丰富的第三方工具和库, 使其易于学习和集成到各种应用中.
-
-
缺点:
- 不适合复杂的事务处理:不支持跨多个文档的复杂事务操作, 因此在需要强一致性的应用中可能不是最佳选择.
- 高存储和内存消耗:由于其灵活的数据模型和索引结构, 可能需要更多的存储空间和内存资源, 特别是在处理大规模数据时.
- 查询性能高度依赖索引:对于复杂查询, 性能可能会受到索引的影响. 如果索引不正确配置或不足够, 查询性能可能会下降.
- 学习曲线:对于那些熟悉传统关系型数据库的开发人员来说, 学习MongoDB的概念和查询语言可能需要一些时间.
- 一致性模型的权衡:采用基于文档的数据模型和柔性的一致性模型, 这可能导致在某些情况下出现数据不一致的问题. 需要仔细考虑一致性要求.
Couchbase
-
优点:
- 高性能: 通过采用内存存储和自动分片等技术, 实现了出色的读取和写入性能. 它特别适用于需要低延迟数据访问的应用程序, 如实时分析和实时应用程序.
- 可伸缩性: 支持水平扩展, 可以通过添加新节点来增加存储容量和处理能力. 这种可伸缩性使其适用于应对不断增长的数据需求.
- 高可用性: 具有内置的数据复制和自动故障转移功能, 确保数据的高可用性. 即使某个节点出现故障, 数据仍然可以访问.
- 灵活的数据模型: 支持面向文档的数据模型, 允许以JSON格式存储和查询数据. 这使得它适用于半结构化数据和灵活的数据模型需求.
- 实时数据访问: 支持实时数据更新和查询, 适用于需要快速响应的应用程序, 如在线游戏、社交媒体和实时监控.
- 全文搜索: 提供全文搜索功能, 通过Elasticsearch插件实现, 允许构建文本搜索应用程序.
- 跨数据中心复制: 支持数据在多个数据中心之间的复制, 实现地理上的冗余和高可用性.
- 多语言支持: 提供多种客户端库, 支持多种编程语言, 方便与各种应用程序堆栈集成.
-
缺点:
- 复杂性: 虽然强大, 但也复杂, 特别是对于初学者来说, 学习曲线可能较陡. 配置和管理可能需要额外的专业知识.
- 限制的查询语言: 的查询语言N1QL虽然强大, 但可能与传统SQL不同, 需要学习新的查询语法.
- 存储成本: 由于在内存中存储数据, 存储成本可能较高, 特别是对于大规模数据集.
- 社区支持: 尽管有活跃的社区, 但与一些其他NoSQL数据库相比, 社区规模较小, 可能限制了可用的学习资源和支持.
总结
| 方面 | MongoDB | Couchbase |
|---|---|---|
| 免费版本 | 提供 | 提供 |
| 商业版本 | 提供, 费用取决于许可证类型、订阅级别和所需的支持水平 | 提供, 费用取决于许可证类型、订阅级别和所需的支持水平 |
| 云版本 | MongoDB Atla, 定价基于云提供商、实例大小和所需的功能 | Couchbase Cloud, 定价基于云提供商、实例大小和所需的功能 |
| 场景 | 半结构化数据, 内容管理系统, IoT 数据, 实时分析, 开发速度优先 | 高性能和低延迟, 大规模的实时应用程序, 全文搜索, 分布式数据, 灵活性和强一致性的权衡 |
| 可扩展性 | 水平扩展, 副本集, 自动分片, 配置灵活性 | 水平和垂直扩展, 自动分片, 内置负载均衡, 副本集 |
| 认证和授权 | 支持多种身份验证机制, 包括SCRAM-SHA-1和X.509证书. 允许管理员为用户分配不同的角色和权限 | 支持多种身份验证机制, 包括LDAP、Active Directory等. 允许管理员为用户分配不同的角色和权限 |
| 加密 | 数据传输的 SSL/TLS 加密. MongoDB Enterprise版提供了静态加密和动态加密 | 数据传输的 SSL/TLS 加密. Couchbase Enterprise 提供了静态加密和动态加密 |
| 审计 | 提供 | 提供 |
| 学习成本 | 较低, 有强大的社区和资源, 支持多种编程语言 | 较高, 学习资源较少, 支持编程语言相对较少 |
使用场景的补充:
- MongoDB
- 半结构化数据: 适用于存储和查询半结构化或文档型数据, 如JSON或BSON文档. 它的灵活数据模型使其非常适合应对数据模式可能变化的情况.
- 内容管理系统: 由于MongoDB的灵活性, 它常常用于内容管理系统 (CMS) 和博客平台, 其中文档可以具有不同的字段和结构.
- IoT数据: 适合用于存储和分析大量的IoT (物联网) 数据, 因为它可以轻松处理来自不同传感器的数据.
- 实时分析: 可以用于实时数据分析, 支持复杂的查询和聚合操作, 适用于实时仪表板和数据报告.
- 开发速度优先: 如果开发速度和快速迭代对项目至关重要, MongoDB的灵活性和无模式数据存储可能是一个优势.
- Couchbase
- 高性能和低延迟: 强调高性能和低延迟, 适用于需要快速响应和实时数据访问的应用程序, 如实时监控、社交媒体和游戏.
- 大规模的实时应用程序: 适用于大规模、高并发的实时应用程序, 如在线游戏、实时投票和实时聊天应用.
- 全文搜索: 提供全文搜索功能, 可以用于构建文本搜索引擎和搜索应用程序.
- 分布式数据: 如果需要在多个数据中心之间复制数据, 以实现地理上的冗余和高可用性, Couchbase的分布式架构是一个优势.
- 灵活性和强一致性的权衡: 允许根据应用程序需求在数据一致性和性能之间进行权衡, 因此适用于需要灵活性的应用程序.
键值存储数据库
Redis (Remote Dictionary Server)
- 优点:
- 高性能:主要将数据存储在内存中,因此具有非常快的读写操作速度。这使得它非常适合作为缓存层,用于加速应用程序的数据访问。
- 支持多种数据结构:支持丰富的数据结构,如字符串、列表、集合、哈希表和有序集合。这使得它非常灵活,可以用于各种不同的用例。
- 持久性选项:可以配置为支持数据持久性,可以将数据保存到磁盘上,以便在重启后恢复数据。
- 分布式特性:支持主从复制,可以通过复制数据到多个节点来提高可用性。它还支持分片,可以水平扩展以处理大规模数据。
- 原子性操作:支持原子性操作,可以在单个命令中执行多个操作,确保数据的完整性。
- 丰富的客户端库:有多种客户端库可供多种编程语言使用,使其易于集成到各种应用中。
- 发布-订阅模式:支持发布-订阅模式,允许应用程序发送和接收实时消息。
- 缺点:
- 内存消耗:将数据存储在内存中,因此对于大规模数据集,它可能需要大量内存。这可能会导致高成本的硬件需求。
- 持久性性能开销:启用持久性选项(如RDB快照或AOF日志)会对性能产生一定的开销,特别是在高写入负载下。
- 单线程模型:采用单线程模型来处理命令,这意味着它在某些情况下可能会受到阻塞。尽管它通过多路复用技术提高了并发性能,但对于高并发写入操作,可能需要仔细优化。
- 不适合复杂查询:主要用于键值存储和简单的数据操作,不适合复杂的查询操作。对于需要复杂查询的应用,关系型数据库可能更合适。
- 缺少安全性特性:默认情况下没有强大的安全性特性,需要额外的配置来限制访问和加强安全性。
列族数据库
HBase
- 优点:
- 高可伸缩性:为大规模数据集设计的,可以轻松扩展以适应不断增长的数据量,通过添加更多的节点来提高容量和性能。
- 高吞吐量:具有出色的读写吞吐量,特别适用于需要快速访问大量数据的应用程序,如日志存储、实时分析等。
- 分布式架构:采用分布式架构,数据存储和查询被分散在多个节点上,这提高了性能和可用性,并具有容错性。
- 面向列的存储:采用面向列的数据模型,这使得它能够高效地处理大规模数据表,适用于列的增量更新和稀疏数据。
- 强一致性:支持强一致性的读取和写入操作,这对于某些应用程序来说是必要的,如金融领域和在线交易。
- 内建版本控制:支持数据版本控制,可以检索和恢复不同时间点的数据版本。
- 与Hadoop生态系统集成:HBase与Hadoop生态系统无缝集成,可以通过MapReduce任务进行数据分析。
- 缺点:
- 复杂性:HBase的配置和管理可能相对复杂,需要深入了解其体系结构和运作方式。
- 不适合小数据:适用于大规模数据存储,对于小规模数据集来说可能过于复杂和笨重。
- 不支持SQL查询:与传统的关系型数据库不同,HBase不支持SQL查询语言。查询需要编写在HBase的API上,这可能对开发人员造成一定的学习曲线。
- 有限的数据处理能力:主要用于读取和写入操作,不支持复杂的数据处理和分析任务。通常需要与Hadoop生态系统中的其他工具一起使用。
- 需要适当的硬件资源:需要大量的硬件资源,包括内存、存储和计算能力,以提供最佳性能。
Apache Cassandra
-
优点:
- 分布式架构:分布式数据库,数据存储在多个节点上,这允许它轻松地水平扩展以处理大规模数据。
- 高可用性:支持多副本数据存储,确保数据的可用性和冗余备份。如果一个节点故障,系统可以自动切换到备用节点。
- 线性可扩展性:通过添加更多的节点,可以线性扩展Cassandra集群,从而提高性能和容量,而无需中断服务。
- 灵活的数据模型:采用键值存储模型,但也支持列族(column-family)存储模型,使其适用于各种数据存储需求。
- 分区容错性:采用分区容错的设计,即使在网络分区情况下,仍可以继续提供服务。
- 快速写入操作:写入操作非常快,因为它将数据先缓存到内存中,然后批量写入到磁盘。
- 丰富的查询语言:支持CQL(Cassandra Query Language),这是一种类似于SQL的查询语言,用于执行复杂的查询操作。
-
缺点:
- 不支持事务:不支持跨多个行或列族的复杂事务操作。它是一个最终一致性的系统,适用于一些特定的应用场景。
- 查询复杂性:虽然支持查询,但它不是为复杂查询而设计的。在某些情况下,需要在应用程序中进行数据建模以支持所需的查询。
- 不适合小规模数据:Cassandra的复杂性和配置要求对于小规模数据集可能过于沉重,更适合大规模数据存储需求。
- 硬件需求:需要适当的硬件资源,包括大量的内存和存储容量,以及高性能的网络。
总结
| 方面 | HBase | Apache Cassandra |
|---|---|---|
| 数据模型 | 面向列的数据模型 | 键值存储和列族存储模型 |
| 数据模型 | 强一致性 | 最终一致性 |
| 查询语言 | ||
| 数据分布 | ||
| 扩展性 | ||
| 数据存储格式 | ||
| 生态系统 |