分布式系统的单点问题
分布式系统的单点问题是一个常见的问题, 可分为无状态服务的单点问题和有状态服务的单点问题.
无状态服务的单点问题
无状态服务:
无状态请求, 服务端所能处理的数据全部来自请求所携带的信息, 无状态服务对于客户端的单次请求, 不依赖于其它请求, 处理一次请求的信息都包含在该请求内. 最典型的就是 web 服务器, 每次 HTTP 请求和之前的都没有关系, 只是获取目标 URL, 得到目标内容, 这次链接内容就被杀死了.
对于无状态的服务, 单点问题的解决比较简单, 因为服务是无状态的, 所以服务节点很容易进行平行扩展. 🌰, 在分布式系统中, 为了降低各进程通信的网络结构的复杂度, 我们会增加代理节点, 专门做消息的转发, 其他的业务直接进行和代理节点的通信, 类似一个星型的网络结构.
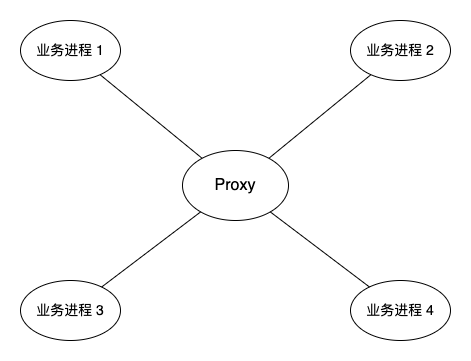
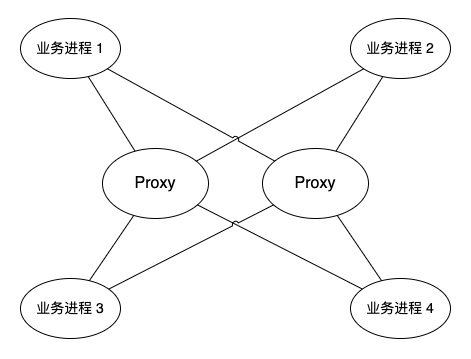
参考上面这两个图, Proxy 是一个消息转发代理, 业务进程中的消息都会经过该代理. 但第一个图中只有一个 Proxy, 如果该节点挂了, 那么所有业务进程都无法进行通信. 由于 Proxy 是无状态的服务, 所以很容易想到第二个图中的解决方案, 增加一个 Proxy 节点, 两个 Proxy 节点是对等的. 新增节点之后, 业务进程需要与两个 Proxy 之间增加一个心跳的机制, 业务进程在发送消息的时候根据 Proxy 的状态, 选择一个可用的 Proxy 进行消息传递. 从负载均衡的角度来看, 如果两个 Proxy 都是存活状态, 业务进程应当随机选择一个 Proxy.
这个方案中存在什么问题?
消息的顺序性问题. 一般来说, 业务的消息都是发送、应答, 再发送、再应答这样的顺序进行的, 在业务中可以保证消息的顺序性. 但是在实际的业务中, 这个方案不能保证消息的顺序性. 比如 业务进程 1 向 业务进程 3 发送 消息 A 和 消息 B, 如果在发送 消息 A 的时候选择了 Proxy 1, 在发送 消息 B 时选择了 Proxy 2, 在分布式的环境中, 就不能确保 消息 A 一定比 消息 B 优先到达.
怎么解决?
其实解决也比较简单, 对于这类对消息顺序有要求的业务, 可以指定对应的 Proxy 进行发送. 比如 消息 A 和 消息 B 都使用 Proxy 1 进行发送, 这样就能保证消息的顺序.
有状态服务的单点问题
有状态服务:
服务端会存储请求上下文相关的数据信息, 先后的请求是可以有关联的. 比如 session 等.
如果在架构中, 有个节点是单点的并且是有状态的, 那么首先考虑的是该节点是否可以去状态, 如果可以, 则优先选择去除状态的方案 (比如把状态存储到后端的可靠 DB 中, 可能存在性能的损耗), 然后就退化成一个无状态服务的单点问题了.
但是并不是所有的服务都是可以去状态的, 比如对于一些业务只能在一个节点中进行处理, 如果在不同的节点中处理的话可能造成状态的不一致, 这类型的业务是无法去除状态的.
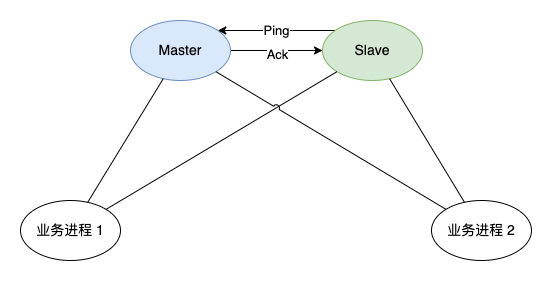
一个方案就是增加一个备用节点, 备用节点和业务进程也可以进行通信, 但是所有的业务消息都发往 Master 节点进行处理. Master 节点和 Slave 节点之间采用 ping 的方式进行通信. Slave 节点会定时发送 ping 包给 Master 节点, Master 节点收到后会响应一个 Ack 包. 当 Slave 节点发现 Master 节点没有响应的时候, 就会认为 Master 节点挂了, 然后把自己升级为 Master 节点, 并且通知业务进程把消息发给自己.
这个方案看起来挺完美的, 当 Master 和 Slave 之间的网络出现问题的时候, Slave 会认为 Master 挂了, 就会升级为 Master, 同样会执行 Master 的相应的业务逻辑, 同样也会生成一些业务数据回写到 DB 中. 但是 Master 是没有挂的, 它同样也在运行对应的业务逻辑 (即使业务进程的消息没有发给旧的 Master 了), 这样就会出现两个 Master 进行写同一份数据了, 造成数据的混乱, 所以说, 这个方案不是一个完美的方案.
方案一: 引入第三方的服务进行裁决
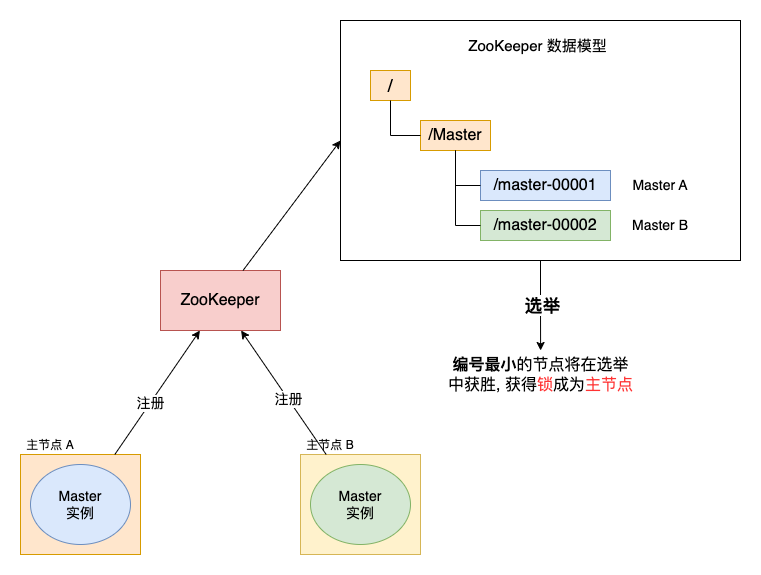
可以引入 ZooKeeper, 由 ZooKeeper 进行裁决. 同样, 启用两个主节点, 节点 A和节点 B. 它们启动之后向 ZooKeeper 去注册一个节点. 假设节点 A注册的节点为master001, 节点 B注册的节点为master002, 注册完成后进行选举, 编号小的节点为真正的节点. 那么, 通过这种方式就完成了对两个 Master 进程的调度.
方案二: 通过选举算法和租约的方式实现 Master 的选举
对于方案一的缺点主要多维护一套 ZooKeeper 的服务, 如果原本业务上并没有部署该服务的话, 要增加该服务的维护也是比较麻烦的事情. 这个时候, 可以在业务进程中加入 Master 的选举方案. 目前有比较成熟的选举算法, 比如 Paxos 和 Raft. 然后再配合租约机制, 就可以实现 Master 的选举, 并且确保当前只有一个 Master 的方案. 比如微信的 PhxPaxos.
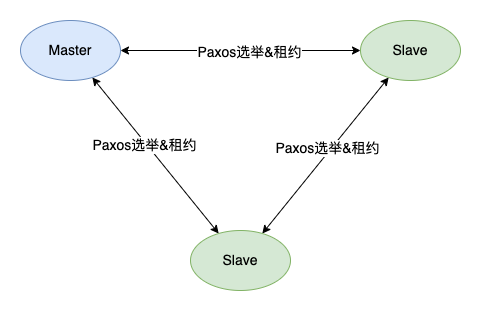
上图的方案中, 三个节点其实都是对等的, 通过选举算法确定一个 Master. 为了确保任何时候都只能存在一个 Master, 需要加入租约的机制. 一个节点成为 Master 之后, Master 和Slave 节点都会进行计时, 在超过租约时间后, 三个节点可以发起 “我要成为 Master” 的请求, 并进行重新选举. 由于三个节点都是对等的, 任何一个都可以成为 Master, 也就是说租期过后, 有可能出现 Master 切换的情况, 所以为了避免 Master 的频繁切换, Master 节点需要比其他节点先发起自己要成为 Master 的请求 (续租), 告诉其他节点我要继续成为 Master, 然后另外的节点收到请求后会进行应答, 正常情况下另外两个节点会同意该请求. 关键点就是, 在租约过期之前, Slave 节点不能发起 “我要成为 Master” 的请求, 这样就可以解决 Master 频繁切换的问题.
常见容错机制
Fail-Over: 失效转移
是一种备份操作模式, 当主要组件异常时, 其功能转移到备份组件. 其要点在于有主有备, 且主故障时备可启用, 并设置为主.
🌰: MySQL 的双 Master 模式, 当正在使用的 Master 出现故障时, 可以拿备 Master 做主使用.
Fail-Back: 失效自动恢复
Fail-Over之后的自动恢复, 在簇网络系统 (有两台或多台服务器互联的网络) 中, 由于要某台服务器进行维修, 需要网络资源和服务暂时重定向到备用系统. 在此之后将网络资源和服务器恢复为由原始主机提供的过程, 称为自动恢复.
🌰: MySQL 的双 Master 模式, 当 Master 故障, 在 Fail-Over 至备 Master, 当主 Master 恢复之后, 则自动切换至主 Master.
Fail-Fast: 快速失败
尽可能的发现系统中的错误, 使系统能够按照事先设定好的错误的流程执行, 对应的方式是 Fault-Tolerant(错误容忍).
🌰: 以 Java 集合 (Collection) 的快速失败为例, 当多个线程对同一个集合的内容进行操作时, 就可能会产生 Fail-Fast 事件. 当某一个 线程A 通过 iterator 去遍历某集合的过程中, 若该集合的内容被其他线程所改变了; 那么 线程A 访问集合时, 就会抛出 ConcurrentModificationException 异常 (发现错误执行设定好的错误的流程), 产生 Fail-Fast 事件.
Fail-Safe: 失效安全
在故障的情况下也不会造成伤害或者尽量减少伤害.
🌰: 写入监控日志出错时, 不会对主业务的成败产生影响.